Decision Trees Algorithm
The decision tree algorithm is a cornerstone in supervised machine learning, adept at tackling both classification and regression challenges.
Its training process involves interrogating the data's features to accurately predict an outcome, be it discrete or continuous.
This algorithm efficiently segments the data into subsets characterized by distinct attributes. It continues this process until it isolates subsets that collectively minimize uncertainty in achieving a specific goal.
Various methods, such as entropy (H) or expected information quantity (I), can quantify the uncertainty in these subsets.
$$ I(X) = - \sum_{i=1}^n P(x_i) \log_s p(x_i) $$
In this formula, 's' represents the total possible events or responses to a query.
Example: Take coin flipping, for instance. The probability p1=0.5 of getting heads and p2=0.5 for tails. The entropy or expected information is calculated as $$ I = - ( \frac{1}{2} \log_2 \frac{1}{2} + \frac{1}{2} \log_2 \frac{1}{2} ) = 1 $$ Here, entropy peaks due to high uncertainty. On the other hand, for a biased coin that always lands heads, p1=1 and P2=0, the entropy drops to $$ I = - ( 1 \log_2 1 + 0 \log_2 0 ) = 0 $$ since the outcome is predetermined.
The concept of information gain plays a pivotal role, measuring the entropy reduction after a dataset is divided based on an attribute.
Visually, the decision tree is depicted as an acyclic graph, where each node represents an attribute, branching out into the attribute's potential values.
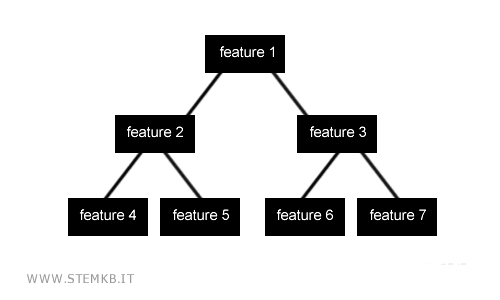
The algorithm's objective is to trace a path through attributes that maximizes certainty and minimizes doubt.
Gain is essentially the entropy difference pre- and post-division of the dataset.
The most efficient tree, in terms of gain, signifies the optimal solution relative to the training dataset provided.




