K-Nearest Neighbors
The K-NN (K-Nearest Neighbors) algorithm is a cornerstone in pattern recognition, operating on the principle of data proximity. It posits a simple yet effective idea: if object A resembles object B in characteristics, it’s highly probable that both belong to the same category. This approach is pivotal in classification challenges within machine learning.
Note: While K-NN is renowned for its simplicity and minimal training resource requirements, its effectiveness in classification varies.
Unpacking the K-NN Algorithm
As a supervised machine learning technique, K-NN necessitates a pre-classified set of examples, known as the training set.
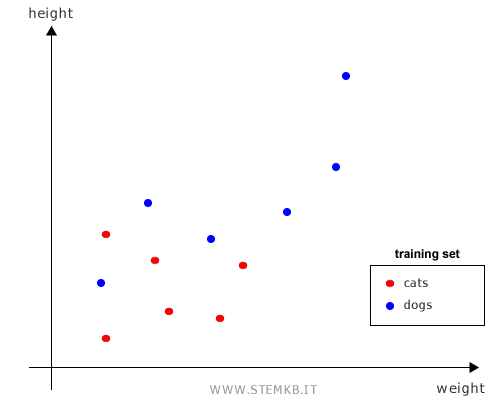
In action, K-NN evaluates new, unclassified data by comparing and classifying them according to their distance from the training set examples.
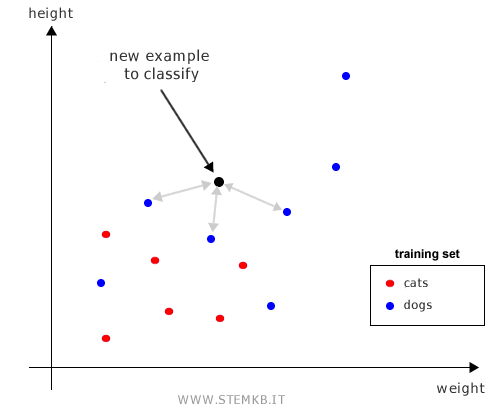
The algorithm employs various methods for distance calculation, such as Euclidean or Manhattan distance for numerical data, and the Hamming distance for string data.
Example
Consider a scenario with only two features. Here, K-NN assesses the K closest training examples relative to the example being classified.
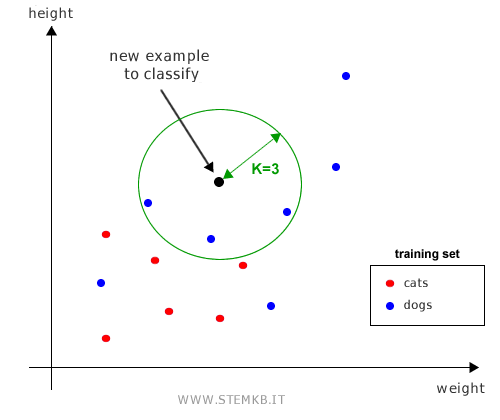
The classification of a new example is influenced by the predominant class within these K nearest examples.
Example: For instance, to classify a black example using K=3, the algorithm looks at the three closest training examples. If these are all blue, the new example is also classified as blue.
Crucially, in K-NN, the selection of the K parameter is a decisive factor.
- A small K means the classification hinges on a limited set of nearest examples, potentially skewing results due to data noise.
- A large K, on the other hand, might dilute individual example characteristics, leading to a bias towards the most frequent category in the overall dataset. This also ramps up the computational load, as calculating distances across a large set of data is both resource and time-intensive.
Note: For binary class problems, it’s generally recommended to set K to an odd number to avoid deadlocks in classification.




