Random Forest Algorithm
The random forest algorithm stands out in the world of supervised machine learning as a robust classifier, primarily utilized in solving complex classification challenges.
This approach involves creating an ensemble of decision trees from a given training dataset, thereby significantly enhancing model reliability beyond what's achievable with a solitary decision tree.
Demystifying the Random Forest Algorithm
At its core, the algorithm begins its journey with a supervised dataset (training set), comprising n attributes X1,...,Xn (features), paired with a target label that denotes the correct classification.
Phase 1
Initially, the random forest algorithm embarks on a tree-building spree:
1.1) It randomly selects a subset of examples from the dataset along with a smaller group of attributes (i
1.2) On this chosen data sample D1, a decision tree is constructed and its findings are recorded.

This is just the beginning of a repetitive process.
Revisiting step 1.1, the algorithm generates another sample D2 and crafts a new decision tree, which may or may not mirror the first.
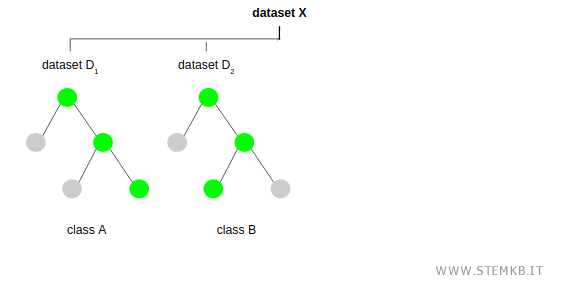
This cycle repeats numerous times, each iteration contributing to a diverse array of decision trees.
Ultimately, the algorithm culminates in a collection of various decision trees derived from distinct random samples of the original dataset.
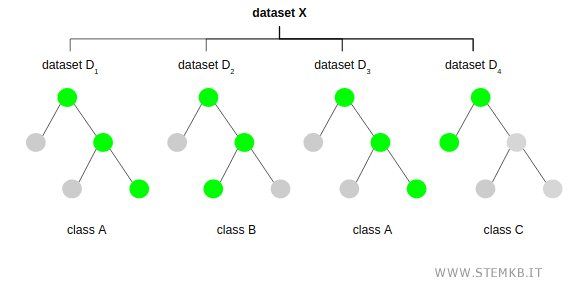
Every tree presents a potential solution or classification, which may align with or diverge from its counterparts, hence the aptly named 'random forest'.
Phase 2
In the second phase, the Random Forest algorithm seeks consensus by pinpointing the most prevalent solution across all trees.
Take, for instance, a scenario where class A emerges as the predominant classification, appearing in two trees, unlike classes B and C, which are less frequent.
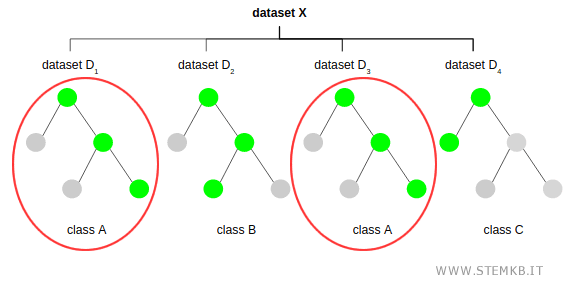
Consequently, the algorithm’s final verdict leans towards class A.
Pros and Cons
While the random forest algorithm adeptly minimizes model variance, it's not without its trade-off in increased BIAS.
A model with high variance tends to overfit to training data, whereas a model with high BIAS might miss underlying patterns in the data, leading to underfitting.




